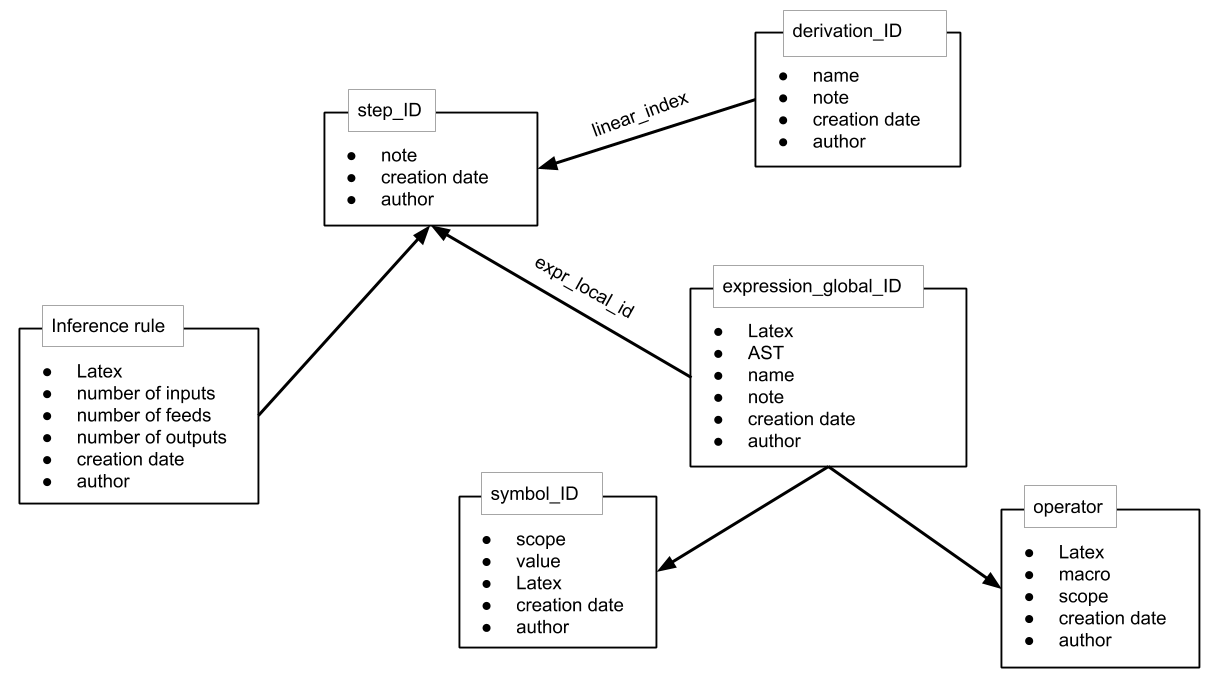
The Physics Derivation Graph has progressed through multiple architectures, with data structure changes keeping pace with the developer's knowledge.
plain text:
databases for comments, connections, equations, operators. Perl script to convert database content to images.
One line per entry in each database.
web interface:
the current implementation.
Uses Python, Flask, Docker.
Data is stored in a JSON file.
Limited support for checking inference rules using Sympy.
Storage formats evolved:
nested Python dictionaries and lists stored as a Python Pickle
nested Python dictionaries and lists stored as a JSON file. With this approach the schema can be validated
nested Python dictionaries and lists stored as a JSON file stored in Redis. Retains the schema validation of JSON while preventing concurrent writes to file; see https://redis.io/topics/transactions
nested Python dictionaries and lists stored as a JSON file stored in SQLite3. Part of the migration towards table-based implementation. SQLite3 is better than Redis because Redis requires a Redis server to be running whereas SQLite3 is a file.
Each of these have required a rewrite of the code from scratch, as well as transfer code (to move from n to n+1).
The author didn't know about property graphs when implementing v1, v2, and v3.
Within a given implementation, there are design decisions with trade-offs to evaluate.
Knowing all the options or consequences is not feasible until one or more are implemented.
Then the inefficiencies can be observed.
Knowledge gained through evolutionary iteration is expensive and takes a lot of time.
A few storage methods were considered and then rejected without a full implementation.
The Physics Derivation Graph can be expressed in RDF.
Each step in a derivation could be put in the subject–predicate–object triple form. For example, suppose the step is
Input 1: y=mx+b
inference rule: multiply both sides by
feed: 2
output 2: 2*y = 2*m*x + 2*b
Putting this in RDF,
step 1 | has input | y=mx+b
step 1 | has inference rule | multiply both sides by
step 1 | has feed | 2
step 1 | has output | 2*y = 2*m*x + 2*b
While it's easy to convert, I am unaware of the advantages of using RDF.
The Physics Derivation Graph is oriented towards visualization.
SPARQL is the query language for RDF. I don't see much use for querying the graph.
Using RDF doesn't help with using a computer algebra system for validation of the step.