Recommendation: Read the user documentation and FAQ first. This page assumes familiarity with the jargon used in the Physics Derivation Graph.
This page provides background context for design decisions and implementation choices associated with the Physics Derivation Graph (PDG). Contributions to the project are welcome; see CONTRIBUTING.md on how to get started. The Physics Derivation Graph is covered by the Creative Commons Attribution 4.0 International License, so if you don't like a choice that was made you are welcome to fork the Physics Derivation Graph project.
Contents
The objective for the Physics Derivation Graph project is to write down all known mathematical physics in a way that can be both read by humans and checked by a computer algebra system. To do that, primary design considerations include how to represent the objects (e.g., inference rules and expressions and symbols) and what data structure is sufficient.
This page describes the current status and historical evoluation of design decisions critical to the Physics Derivation Graph.
The visualization of a graph with expressions and inference rules as nodes relies on each node having a distinct index. Each expression, symbol, and inference rule appears only once in the database. This is made possible through use of unique IDs associated with every facet of the visualization. To see what this means in terms of the "period and frequency" example on the homepage, here is a view of the indices supporting that visualization for two sequential steps:
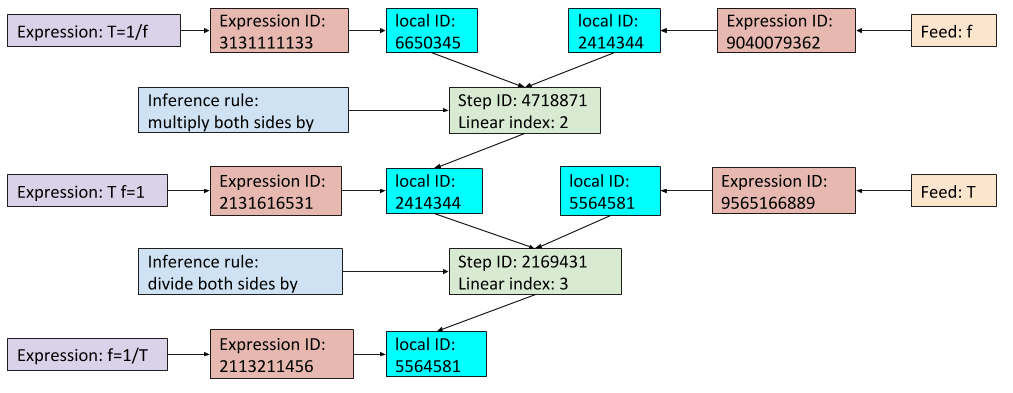
Manipulating these indices underlies all other tasks in the Physics Derivation Graph. Access to these indices is performed through a single data structure.
The Physics Derivation Graph is currently stored in a single JSON file. The JSON file is read into Python as a dictionary.
JSON is convenient because it is plain text and the ease of detailed validation available using schemas. The many alternatives to JSON (e.g., SQLite, Redis, Python Pickle, CSV, GraphML) offer trade-offs, a few of which have been explored.
There are multiple choices of how to represent a mathematical expression. The choices feature trade-offs between conciseness, ability to express the range of notations necessary for Physics, symantic meaning, and ability to use the expression in a computer algebra system (CAS). See the comparison of syntax below. \(\rm\LaTeX\) was selected primarily because of the common use in Physics, display of complex math, conciseness, and expressiveness. The use of \(\rm\LaTeX\) means other tasks like parsing symbols and resolving ambiguity are harder.
Although the Physics Derivation Graph is intended to be comprehensive across domains, there are aspect of Physics not within the current scope of the project: