 Figure 2.
Figure 2.
Recommendation: Read the user documentation, FAQ, and design documentation first. This page assumes familiarity with the jargon used in the Physics Derivation Graph.
This page provides developer guidance for the Physics Derivation Graph (PDG). Contributions to the project are welcome; see CONTRIBUTING.md on how to get started. The Physics Derivation Graph is covered by the Creative Commons Attribution 4.0 International License, so if you don't like a choice that was made you are welcome to fork the Physics Derivation Graph project.
Looking for the API? See API documentation.
Contents
The complexity supporting a technology is proportional to the number of abstraction layers required to enable it.
Python as a "glue" language is leveraged to connect existing tools like \(\rm\LaTeX\), Flask, logging, manipulation of data. Also, Python is the language the project owner is most comfortable with. And it is free and open source.
Python libraries: matplotlib, black, mypy, pycallgraph, gunicorn, prospector, pandas, jsonschema, sympy, antlr4-python3-runtime, flask-wft, graphviz
The model-view-controller (MVC) is a way to separate presentation from the backend computation and data transformation.
Note on using MVC with Flask and WTForms: For webpages with forms, the form submission should return to controller.py rather than linking to next page.
Containerization provides documentation of software dependencies and shows the installation process, enabling reproducibility and platform independence.
Alpine was investigated as a candidate OS but was found to be insufficient. Ubuntu provides necessary packages.
To provide a web interface, Flask is used. HTML (with Javascript) pages are rendered using Jinja2. Mathematical expressions rely on MathJax Javascript. Flask is not intended for production use in serving Python applications, so Gunicorn is the Web Server Gateway Interface. Nginx provides an HTTP proxy server.
Why this complexity is relevant is addressed in this StackOverflow answer.
Latex, dvipng, texlive
git, github
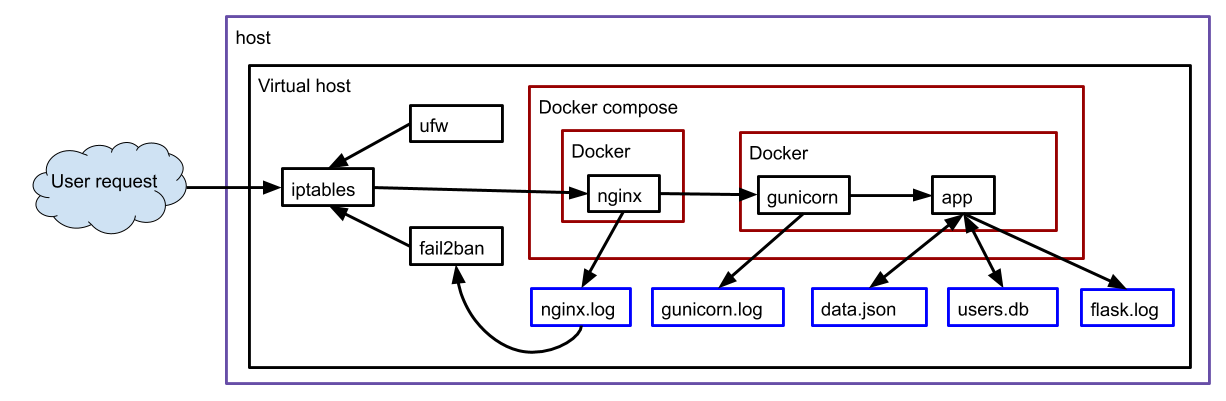
The following is an illustration of the various software interactions that are used in this website.
Figure 2.
Quick start on the command line:
git clone https://github.com/allofphysicsgraph/ui_v7_website_flask_json.git
cd ui_v7_website_flask_json/flask/
docker build -t flask_ub .
docker run -it --rm -v`pwd`/data.json:/home/appuser/app/data.json \
-v`pwd`/logs/:/home/appuser/app/logs/ \
--publish 5000:5000 flask_ub
To enter the container, run the commands
docker run -it --rm -v`pwd`:/scratch \
-v`pwd`/data.json:/home/appuser/app/data.json \
-v`pwd`/logs/:/home/appuser/app/logs/ \
--entrypoint='' \
--publish 5000:5000 flask_ub /bin/bash
python controller.py
Inside the container there is also a Makefile with code maintenance tools
docker run -it --rm -v`pwd`:/scratch \
-v`pwd`/data.json:/home/appuser/app/data.json \
-v`pwd`/logs/:/home/appuser/app/logs/ \
--entrypoint='' \
--publish 5000:5000 flask_ub /bin/bash
make
Quick start on the command line:
git clone https://github.com/allofphysicsgraph/ui_v7_website_flask_json.git
cd ui_v7_website_flask_json/flask/
docker build -t gunicorn_ub --file Dockerfile.gunicorn .
docker run -it --rm -v`pwd`:/scratch \
-v`pwd`/data.json:/home/appuser/app/data.json \
-v`pwd`/logs/:/home/appuser/app/logs/ \
--entrypoint='' \
--publish 5000:5000 gunicorn_ub /bin/bash
gunicorn --bind :5000 wsgi:app \
--log-level=debug \
--access-logfile logs/gunicorn_access.log \
--error-logfile logs/gunicorn_error.log
Much of the current codebase is focused on managing the numeric IDs associated with every facet of the database. This workload is due to not using a property graph representation (e.g., Neo4j). If I used Neo4j, I wouldn't need to track all the IDs and I could instead just work with the data. I've decided to stick with JSON and managing numeric IDs since I won't want to use proprietary software. (Neo4j community edition is open source, but I'm wary of the ties to a commercial product.)
After checking out the github repo, I navigate to
ui_v7_website_flask_json/flask and then run
make dockerlive and then open Firefox to https://localhost:5000.
The purpose of this section is to address the question, What happened when that docker container ran and the webpage was opened?
Understanding the answer relies on knowing Python, Flask, and the Model-View-Controller paradigm.
The entry point for the program is controller.py.
That file primarily depends on compute.py.
The purpose of compute.py is to manage the Python dictionary of nested dictionaries in the variable dat that is read from the JSON file.
All the additions, edits, and transformations to dat are performed in compute.py and then provided to controller.py for use in dynamically generating the HTML+Javascript pages using Jinja2.
The starting point of controller.py is at the bottom of the file with the line if __name__ == "__main__".
That is where the Flask app is started. Once the app is running, the web browser requests use the function decorators like @app.route("/",...) to run corresponding functions like def index():.
Each of the decorated Python functions in controller.py rely on functions defined in compute.py.
All of the calls from controller.py to compute.py are wrapped in try/except clauses so that if the Python fails, the user is not exposed to the failure stack trace.
Each of the decorated Python functions in controller.py terminate with either return render_template(... or return redirect(... which results in the user's web browser getting a new page of content.
When errors occur, there's a Flask function flash used to convey the error summary to the user (displayed at the bottom of the webpage).
The website derivationmap.net is run using docker-compose; see ui_v7_website_flask_json
When a web browser requests the page
https://derivationmap.net/developer_documentation
nginx calls gunicorn calls
controller.py
with the URL string. The Python flask package uses the URL information to
call the relevant Python function. For example, requesting list_all_derivations
invokes the function def list_all_derivations():. That
Python function relies on functions in
computer.py
to get data from the data.json database.
Second, I use a Makefile to ensure the commands required to run Docker are documented.# Physics Derivation Graph # Ben Payne, 2021 # https://creativecommons.org/licenses/by/4.0/ # Attribution 4.0 International (CC BY 4.0) # https://docs.docker.com/engine/reference/builder/#from # https://github.com/phusion/baseimage-docker FROM phusion/baseimage:0.11 # PYTHONDONTWRITEBYTECODE: Prevents Python from writing pyc files to disk (equivalent to python -B option) ENV PYTHONDONTWRITEBYTECODE 1 # https://docs.docker.com/engine/reference/builder/#run RUN apt-get update && \ apt-get install -y \ python3 \ python3-pip \ python3-dev \ && rm -rf /var/lib/apt/lists/*
# Creative Commons Attribution 4.0 International License # https://creativecommons.org/licenses/by/4.0/ # .PHONY: help clean webserver typehints flake8 pylint doctest mccabe help: @echo "make help" @echo " this message" @echo "make docker" @echo " build and run docker" @echo "make dockerlive" @echo " build and run docker /bin/bash" docker: docker build -t flask_ub . docker run -it --rm \ --publish 5000:5000 flask_ub dockerlive: docker build -t flask_ub . docker run -it --rm -v`pwd`:/scratch \ --publish 5000:5000 flask_ub /bin/bash
controller.py# Physics Derivation Graph # Ben Payne, 2021 # https://creativecommons.org/licenses/by/4.0/ # Attribution 4.0 International (CC BY 4.0) # https://docs.docker.com/engine/reference/builder/#from # https://github.com/phusion/baseimage-docker FROM phusion/baseimage:0.11 # PYTHONDONTWRITEBYTECODE: Prevents Python from writing pyc files to disk (equivalent to python -B option) ENV PYTHONDONTWRITEBYTECODE 1 # https://docs.docker.com/engine/reference/builder/#run RUN apt-get update && \ apt-get install -y \ python3 \ python3-pip \ python3-dev \ && rm -rf /var/lib/apt/lists/* # https://docs.docker.com/engine/reference/builder/#copy # requirements.txt contains a list of the Python packages needed for the PDG COPY requirements.txt /tmp RUN pip3 install -r /tmp/requirements.txt COPY controller.py /opt/ # There can only be one CMD instruction in a Dockerfile # The CMD instruction should be used to run the software contained by your image, along with any arguments. CMD ["/opt/controller.py"]
requirements.txt#!/usr/bin/env python3 # Physics Derivation Graph # Ben Payne, 2021 # https://creativecommons.org/licenses/by/4.0/ # Attribution 4.0 International (CC BY 4.0) # https://hplgit.github.io/web4sciapps/doc/pub/._web4sa_flask004.html from flask import ( Flask, redirect, render_template, request, url_for ) app = Flask(__name__, static_folder="static") app.config.from_object( Config ) # https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-iii-web-forms app.config["DEBUG"] = True @app.route("/index", methods=["GET", "POST"]) @app.route("/", methods=["GET", "POST"]) def index(): """ the index is a static page intended to be the landing page for new users >>> index() """ trace_id = str(random.randint(1000000, 9999999)) logger.info("[trace page start " + trace_id + "]") try: d3js_json_filename = compute.create_d3js_json("884319", path_to_db) except Exception as err: logger.error(str(err)) flash(str(err)) d3js_json_filename = "" dat = clib.read_db(path_to_db) logger.info("[trace page end " + trace_id + "]") return render_template("index.html", json_for_d3js=d3js_json_filename) if __name__ == "__main__": # app.run(debug=True, host="0.0.0.0") # EOF
Flask